Supplemental info about phylodiversity in evolutionary computation
2021-09-09
Chapter 1 Introduction
This is the supplemental material for our work, ‘What can phylogenetic metrics tell us about useful diversity in evolutionary algorithms?’. This is not intended as a stand-alone document, but as a companion to our paper.
1.1 About our supplemental material
As you may have noticed (unless you’re reading a pdf version of this), our supplemental material is hosted using GitHub pages. We compiled our data analyses and supplemental documentation into this nifty web-accessible book using bookdown.
The source code/configuration files for this supplemental material and all experiments in the paper can be found in this GitHub repository.
1.3 Research overview
1.3.1 Abstract
It is generally accepted that “diversity” is associated with success in evolutionary algorithms. However, diversity is a broad concept that can be measured and defined in a multitude of ways. To date, most evolutionary computation research has measured diversity using the richness and/or evenness of a particular genotypic or phenotypic property. While these metrics are informative, we hypothesize that other diversity metrics are more strongly predictive of success. Phylogenetic diversity metrics are a class of metrics popularly used in biology, which take into account the evolutionary history of a population. Here, we investigate the extent to which 1) these metrics provide different information than those traditionally used in evolutionary computation, and 2) these metrics better predict the long-term success of a run of evolutionary computation. We find that, in most cases, phylogenetic metrics behave meaningfully differently from other diversity metrics. Moreover, our results suggest that phylogenetic diversity is indeed a better predictor of success.
1.3.2 Phenotypic diversity vs phylogenetic diversity.
In short, phenotypic diversity measures the diversity of phenotypes in the population at any one point in time. Phylogenetic diveristy measures the diversity of evolutionary history represented in a population. We wrote a lot more about building phylogenies in the context of computational evolution in this paper.
As an example, the following figure shows two different phylogenies (ancestry trees). Arrows show parent-child relationships. Each node is a taxonomically unique phenotype (i.e., a phenotype with a unique evolutionary origin). For simplicity, leaf nodes in these diagrams are assumed to be the current set of taxa in the population; in reality, there could be non-leaf nodes corresponding to extant taxa. A) A population with high phenotypic diversity (phenotypic richness = 5) and low phylogenetic diversity (mean pairwise distance = 2). B) A population with low phenotypic diversity (phenotypic richness = 2) and high phylogenetic diversity (mean pairwise distance = 6).
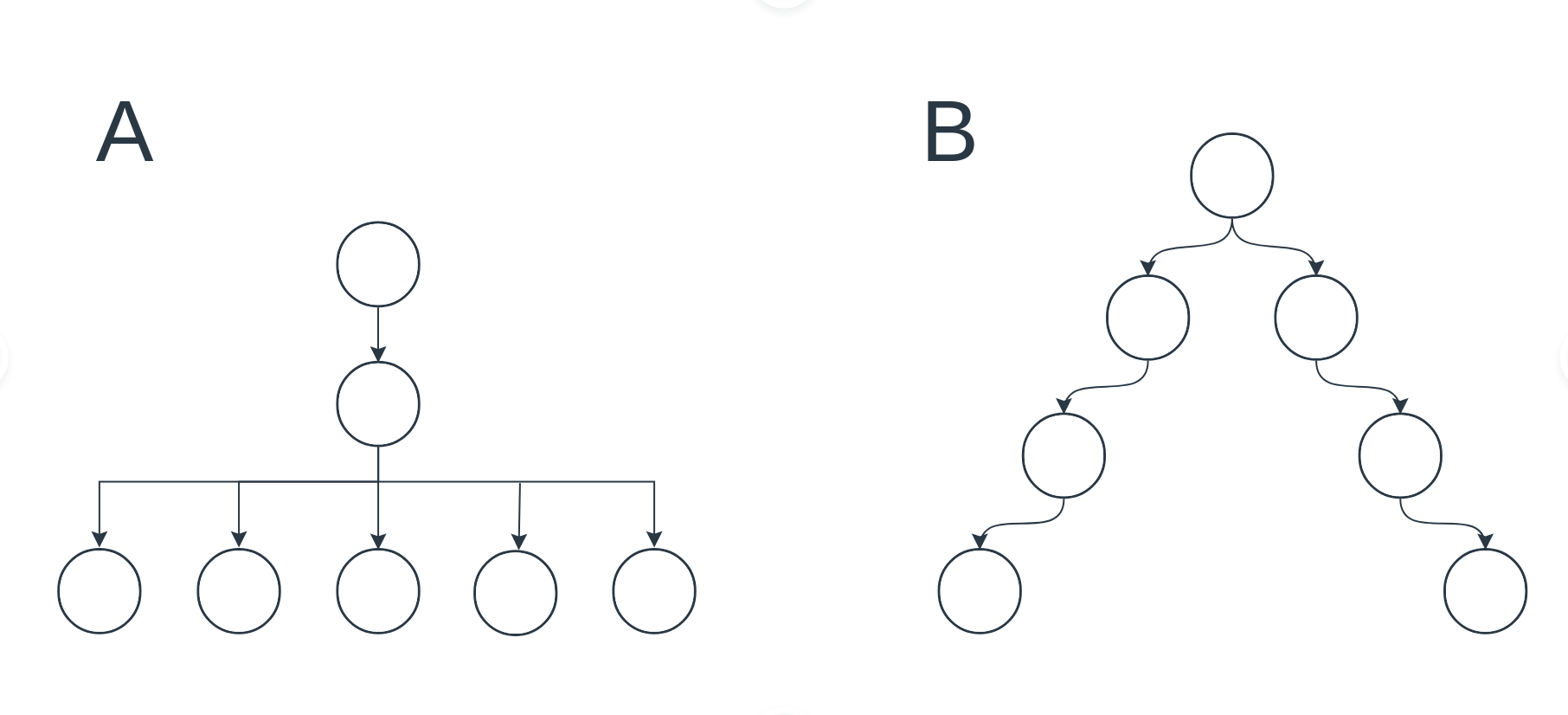
Example of populations with different levels of phenotypic and phylogenetic diveristy
1.3.3 Research questions
- Is phylogenetic diversity meaningfully different from phenotypic diversity in the context of evolutionary computation?
The answer to this question is important. Intuitively, we might think that since these are both types of diversity, they should correlate pretty closely. Given that phylogenetic diversity is more computationally intensive to measure, if we’re going to argue that it’s something evolutionary computation researchers should pay attention to (spoilers: we are!), we need to show that it is meaningfully different.
- Is phylogenetic diversity more informative about outcomes in evolutionary computation than phenotypic diversity?
The importance of this question is more obvious. We know that diversity is centrally linked to the success of evolutionary algorithms. There are hints scattered across the literature that certain types of diversity are more “useful” to solving problems than others. So our goal is for this work to move us towards a better understanding of which types of diversity we should be promoting in evolutionary algorithms.
1.3.4 Study design
We ran 5 selection schemes (random, tournament, fitness sharing, lexicase selection, and eco-ea) on 5 different problems (one designed to be a clean test environment, and 4 chosen to evoke the messy realities of real problems) and gathered a ludicrous amount of data. Here and in the paper, we attempt to focus very closely on getting answers to the two specific questions that we asked above (to avoid overwhelming ourselves or the reader with a firehose of data). There are many intriguing aspects of this data set that raise further questions, which we look forward to addressing in the future.
1.3.5 Results
Phylogenetic diversity and phenotypic diversity behave differently to an extent that was even surprising to us.
Phylogenetic diversity is more predictive of success than phenotypic diversity in the vast majority of cases. The differences are often substantial (check out our effect sizes!).
1.3.6 Caveats/areas for future research
Phylogenetic diversity and phenotypic diversity are both broad classes of metrics, and there is substantial variation in how different phylogenetic diversity metrics behave in different contexts.
There is clearly variation in all of this over time and by fitness landscape.
1.4 Reproducing our work
1.4.1 Data availability
All data used in the paper is available via the Open Science Framework.
1.4.2 Code availability
All code used in the paper is available on github.
1.4.3 Dependencies
The C++ code to run these experiments requires: - Empirical - The EC Ecology toolbox
1.4.4 Compilation
You can compile and run the code used in the paper as follows:
# Clone Empirical
git clone --recursive https://github.com/devosoft/Empirical.git
# Clone EC-ecology-toolbox
git clone https://github.com/emilydolson/ec_ecology_toolbox.git
# Clone the repo for this project
git clone --recursive https://github.com/emilydolson/phylodiversity-metrics-in-EC-GPTP-2021.git
### Complex fitness landscapes
# Compile the executable to run experiments for this project
make
# Run an experiment. To set parameters, use command line flags
# e.g. to set the selection scheme, run ./ecology_parameter_sweep -SELECTION 2
# To see all options, run ./ecology_parameter_sweep --help
./ecology_parameter_sweep
### Exploration diagnostic
# all of the code for the exploration diagnostic lives in the exploration_diagnostic submodule
cd exploration_diagnostic
make
./dia_world
# the dia_world executable can be configured in the same way as the ecology_parameter_sweep executable